The Full Transformer LM
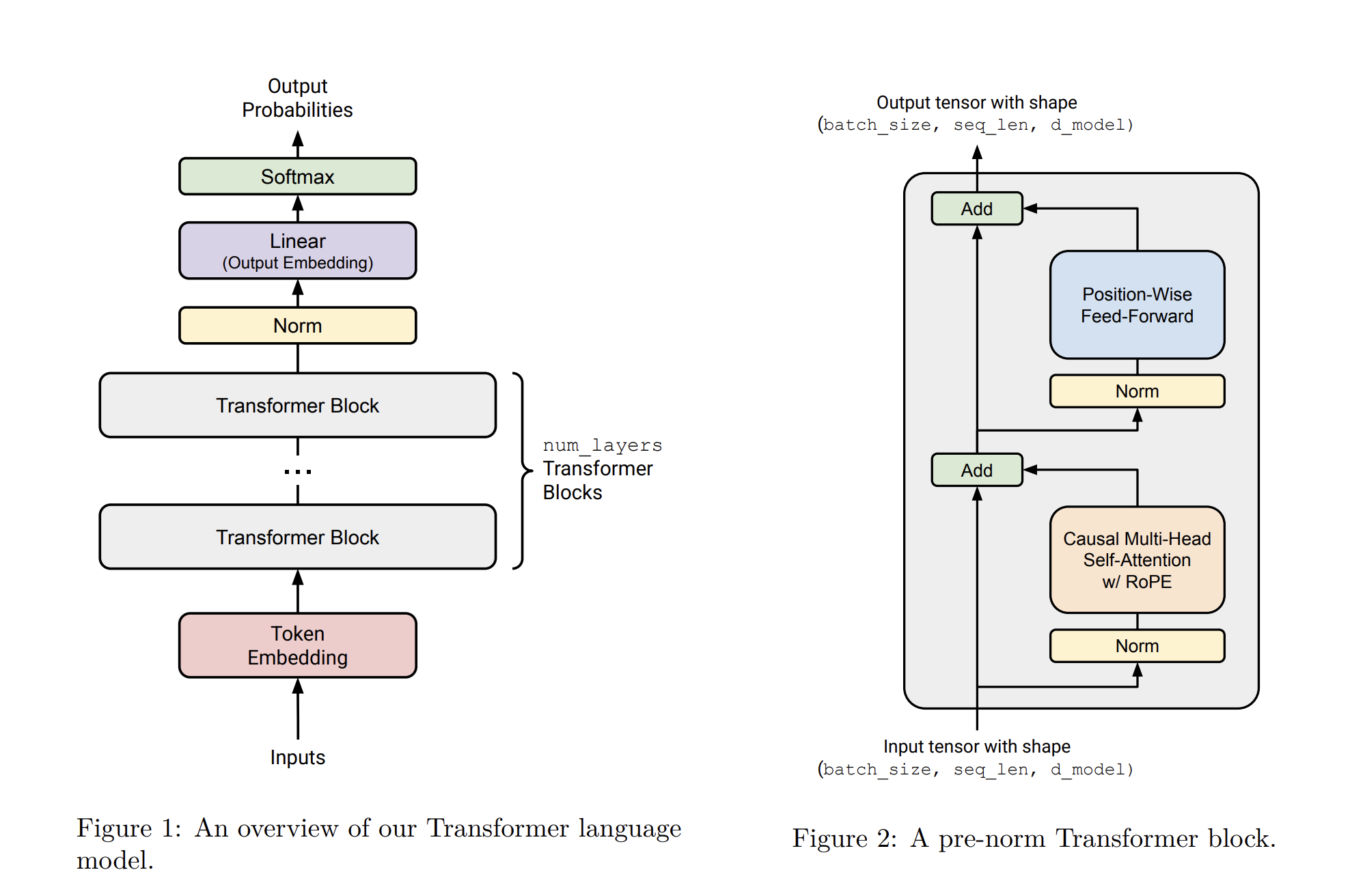
First, let’s implement the transformer block shown here in Figure 2. A Transformer block contains two ‘sublayers’, one for the multihead self attention, and another for the feed-forward network. In each sublayer, we first perform RMSNorm, then the main operation (MHA/FF), finally adding in the residual connection.
To be concrete, the first half (the first ‘sub-layer’) of the Transformer block should be implementing the following set of updates to produce an output from an input ,
how it all fits together
ok so basically tokens come in → we give each one a position with RoPE → then for each transformer block we do RMSNorm → multi-head self-attention (where each token figures out what other tokens to care about via scaled dot-product attention + Softmax) → add the residual → RMSNorm again → feed-forward network (SwiGLU) → add the residual again → repeat for each block → out come logits → Cross-Entropy Loss to see how bad we did → Optimizers to update the weights
9/17/25